

| Programmer to ProgrammerTM | |||||
| |
|||||
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
| |||||||||||||||||||
| The ASPToday
Article December 29, 2000 |
Previous
article - December 28, 2000 |
Next
article - January 2, 2001 | |||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
| ABSTRACT |
| ||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||
| Article Discussion | Rate this article | Related Links | Index Entries | ||||||||
| ARTICLE | |||||||||||
There has been quite a bit of hype about XML in the past few years. Some people see it as a universal fix for all data management problems. Others see it as another non-standardized technology that could end up destroying the web because of its pure extensible nature. Of course, XML really falls somewhere in the middle. It won't fix every data storage and exchange problem you will ever face, but it's definitely not useless! In this article, I will be showing a practical application of XML by building a content management system that consolidates several related XML technologies into a manageable, worthwhile program.
In this article, we make use of the DOM via the MSXML parser, XML, and XSL(T). If you haven't already, I highly recommend downloading the MSXML 3.0 SDK. This article is an implementation of these technologies. We won't be covering their specifics and syntax (except for a few common pitfalls and some techniques).
This system will manage technical articles written by authors using a standard XML schema definition, XSLT for the transformation of articles, and ASP to create the actual application that drives the web site. Of course, such a system could be implemented for any number of data sets (for example, newspaper columns, magazines, recipes). This system should also be able to manage different types of articles given categories or even sub-categories.
Here's a screen shot of the user interface:
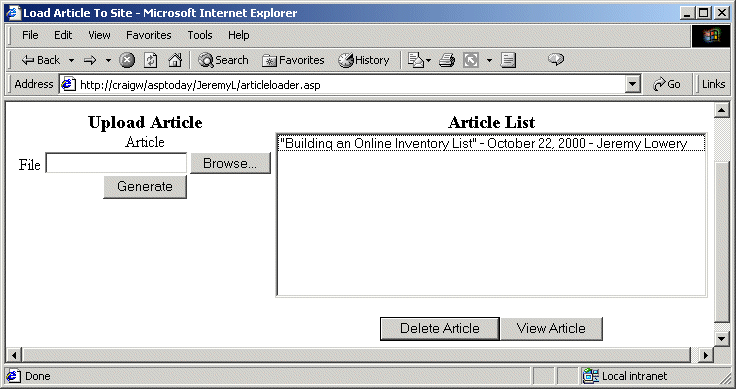
XML's facilities are a perfect match for such a system. We could have a master XML file that maintained list of all articles. For speed, we could break the master article list into individual category files that held article lists for each independent category. As stated in Microsoft's Extreme XML Column, Mike Moore notes that the optimal file size of XML documents is around 50 KB. So based on this, you could break apart each category file into separate XML files for speed if you wished (perhaps alphabetical files). And just for perks, we could allow multi-page articles. By using XSLT and ASP we could generate each "section" of the XML document into different pages, and add a built in linking structure for each page.
Here's a figure showing the steps needed to generate a new article:

In this system, I have decided to apply all of the XSLT transformation while the article is being uploaded. When a user decides to view the article, it will already be in HTML format. The file will have a .asp extension and not .html because authors will have the option to have ASP code executed in their article. Also, using a .asp extension gives us the ability to use SSI if we chose to.
However, we could use other methods here. All articles could be stored in XML files on the server, and when someone requests the article, the transformation could take place then. I opted to take the approach I do here for several reasons:
Obviously, for a simple project, this is a major overkill. However, this application will show the two most common uses of XML: seperating content from appearance, and using it as a data storage format. The wonderful thing is, you can use the same technologies to make such a system as complex and dynamic or as simplistic as you want.
Let's walk through the XML files for the application.
All XML articles will have a meta element containing information about the author, date, and category:
<?xml version="1.0"?>
<article xmlns="x-schema:http://myurl.com/bin/Schemas/article.xsd"
xmlns:html="http://www.w3.org/1999/html">
<meta>
<title>Building an Online Inventory List</title>
<author>Jeremy Lowery</author>
<date>October 22, 2000</date>
<category>Database</category>
<page_count type="multiple" />
<caption>Learn how to use ADO with ASP, SQL, and MS Access by building an
online inventory list.</caption>
</meta>
Based on the page_count element, the article may have one or many section elements. Each section element will represent a page of the article:
<section title="Database Basics">
<text>
One of the most appealing features ASP has to offer is it's integrated
Database support. ASP connects to data sources using another Microsoft
technology called
<html:a href="http://microsoft.com/data/ado/default.htm" target="_new">
ActiveX Data Objects</html:a>(ADO). I say data sources because databases
are only one of the resources ADO can access. However, databases are what
we're going to be focusing on in this article.
</text>
...
</section>
<section title="ADO Basics">
<text>ADO is the "glue" that we use to connect ASP to datastores. We create
ADO objects in our ASP code by using Server.CreateObject(), and
manipulate data via these objects. In this article, I will cover:
</text>
<html:ul>
<html:li>The Connection Object</html:li>
<html:li>The Recordset Object</html:li>
</html:ul>
<text title="The Connection Object">
An ADO Connection Object represents the actual connection to a datasource.
We use the Open method of the Connection object to create the link to the
data store.
</text>
<code><![CDATA[<%
Dim objConn 'Connection Object
'Creation of Object
Set objConn = Server.CreateObject("ADODB.Connection")
'Open the Connection
objConn.Open connection_string
%>
]]>
</code>
...
</section>
</article>
I have thrown in a little bit of everything that an author would need to write a technical article (such as this one!). Authors can use the html namespace for common things such as lists and bullets, there is also a code element authors would use to display source code fragments.
The XML store files include the main article list, and a file for each article category. These will be the files that ASP pages query to get lists of articles and search for files. For example, they might look something like this:
<?xml version="1.0"?>
<articles>
<article ref="building_an_online_inventory_list">
<title>Building an Online Inventory List</title>
<author>Jeremy Lowery</author>
<date>October 22, 2000</date>
<page_count></page_count>
<category>Database</category>
<caption>Learn how to use ADO with ASP, SQL, and MS Access by building an
online inventory list. </caption>
</article>
</articles>
The Schema
Of course, while developing such an application, it is imperative that you have a uniform document schema or DTD that your authors would follow. They could do all of the validating and testing themselves on their own machines using an XSLT template and a remote schema. I have included one in the source code for this article. Since schemas are not my target in this article, I will not be discussing them any further.
Well, I suppose it's time to dive into the code! The ASP code listed in this article is a simplfied version of the file that comes with the code download for the article. That's because, for the purpose of readability, I have removed a lot of the mundane error checking that is a MUST in production code, especially when working with XML. For completeness, you should always check the parseError method of your XML objects after they are loaded:
MyXml.load("myfile.xml")
If MyXml.parseError <> 0 Then
'Oops! Error occurred!
Alright, on with the code.
The most difficult thing to accomplish in such a system is actually creating the article. This is done in the GenerateArticle function. We pass in the variable strSourceFile , which is the path to the XML article document, and load that file:
Function GenerateArticle(strSourceFile)
Set xmlSource = Server.CreateObject("MSXML2.DOMDocument.3.0")
xmlSource.async = false
xmlSource.load(strSourceFile)
Then get the title of the article:
Set doc = xmlSource.documentElement
Set node = doc.selectSinglenode("/article/meta/title")
strArticleTitle = node.text
And load up the master article list to see if the article already exists:
Set xmlStore = Server.CreateObject("MSXML2.DOMDocument.3.0")
xmlStore.async = false
xmlStore.load("master_article_list.xml")
Set doc = xmlStore.documentElement
For Each node in doc.childNodes
If CStr(node.selectSinglenode("title").text) = CStr(strArticleTitle) Then
Response.Write "There is already an article with the title """ &_
strArticleTitle & """<br />"
Exit Function
End If
Next
Here is where the application really gets interesting. The rest of this function will be using different XSLT style sheets to massage the XML article. Using style sheets like this, we can throw something in any number of times, and we always get the same thing out. We could use the DOM to perform such tasks, but XSLT is just fun! In addition, using XSLT is much faster than the DOM. This is because you only have to make one call through the COM layer.
In the following code snippets, we will be alternating from ASP to XSLT and back again.
First off, we need to create the XML fragment that we will be inserting into the relevant XML store files. This fragment will be appended to the master article list and the category list. Here is the part of the XSL template ( store_node_transform.xsl ) that does it:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<xsl:apply-templates />
</xsl:template>
<xsl:template match="article">
<xsl:apply-templates />
</xsl:template>
<xsl:template match="meta">
<article>
<xsl:attribute name="ref">
<xsl:value-of select="title" />
</xsl:attribute>
<title>
<xsl:value-of select="title" />
</title>
<!-- some more of the meta child elements go here -->
</article>
</xsl:template>
</xsl:stylesheet>
Generating a Filename
Now we need to get a filename for the new article. This will be the filename of the article on the server after it as been converted into HTML. We will use the ref attribute of the article store fragment to refer to the filename of the article. We could use an ID number, but I opted to use the title of the article (although we do have to remove all of the spaces and punctuation for the actual file name). No two articles will ever have the same title, so I decided to use this as my "primary key" so to speak.
In addition, users find it easier to remember article URLs than ID numbers: http://www.mydomain.com/bin/ado_basics.asp is more intuitive than, say, http://www.mydomain.com/bin/134234234.asp .
For the category files, I also decided to use the category name. So we need to get the ref attribute and category file name, and remove punctuation and spaces from it like the article title:
Set xslStore = Server.CreateObject("MSXML2.DOMDocument.3.0")
Set xmlStoreNode = Server.CreateObject("MSXML2.DOMDocument.3.0")
' apply the above stylesheet and create the store node
Call xmlSource.transformNodeToObject(xslStore, xmlStoreNode)
' Convert the title into a valid filename
Set doc = xmlStoreNode.documentElement
' get the ref attribute
strArticleID = doc.selectSinglenode("/article").getAttribute("ref")
' TransFormTitle removes all punctuation and replaces spaces with underscores
strArticleID = TransFormTitle(strArticleID)
' Assign the new transformed ref attribute back into the store node
doc.selectSinglenode("/article/@ref").value = strArticleID
' Get the categoy name and transform it to get the category filename
strCategory = doc.selectSinglenode("/article/category").text
strCategory = TransformTitle(strCategory)
Updating the XML Stores
Now we add the store fragment we've generated from our XML article to the master article list. We will also be adding this fragment to the category store in a minute. Therefore, we will really need two of these nodes. When we append an XML fragment to an XML document using appendChild , the fragment is no longer stored in the variable. So, before we start appending, we need to make a copy of the fragment.
Set xmlStoreNode2 = Server.CreateObject("MSXML2.DOMDocument.3.0")
' the true in cloneNode means a deep copy
Set xmlStoreNode2.documentElement = _
xmlStoreNode.documentElement.cloneNode(true)
Now we append the store nodes to the main store list:
' Add new article to main xmlStore xmlStore.documentElement.appendChild(xmlStoreNode.documentElement) xmlStore.save( "master_article_list.xml") Getting the Category
The category structure of the site is stored in another XML file named category_def.xml . This file contains all of the categories being used on the site. We can use this file to determine if the new article is in one of the categories listed. Here is a sample of category_def.xml :
<?xml version="1.0"?>
<article_categories>
<category id="1">
<title>General</title>
<ref>general.xml</ref>
<description />
</category>
<category id="2">
<title>Database</title>
<ref>database.xml</ref>
<description />
</category>
<category id="3">
<title>Applications</title>
<ref>application.xml</ref>
<description />
</category>
...
</article_categories>
This is really a small detail, but we query this file for the category list we want to append our store fragment to. In the GetCategoryFile function, we use the new MSXML XPath facility by calling the setProperty method of the MSXML object. This function returns an MSXML object that has loaded the specific category file, or nothing if there's an error:
Function GetCategoryFile(strCategory)
Set GetCategoryFile = Nothing
Dim objCatList, objNode, strFile, strError, objCat
Set objCatList = Server.CreateObject("MSXML2.DOMDocument.3.0")
objCatList.async = false
objCatList.load "category_def.xml"
objCatList.setProperty "SelectionLanguage", "XPath"
Set objNode = objCatList.documentElement.selectSinglenode _
("/article_categories/category[title = '" & strCategory & "']")
If objNode Is Nothing Then
Response.Write "function GetCategoryFile : " & strCategory & _
" is not a valid category."
Exit Function
End If
Set objCat = Server.CreateObject("MSXML2.DOMDocument.3.0")
objCat.async = false
objCat.load objNode.selectSinglenode("ref").text
Set GetCategoryFile = objCat
End Function
Now back in our main GenerateArticle function, we use it like so:
' Add new article to category store Set xmlStore = GetCategoryFile(strCategory) If xmlStore Is nothing then _ Exit Function xmlStore.documentElement.appendChild(xmlStoreNode2.documentElement) xmlStore.save(strCategory & ".xml") Generating the Actual Article
We now have all of the references to our article done. The only thing left to do is actually generate the article! There are two scenarios that can take place here. If the article is a single page, we only have to apply a style sheet to it and save it. If the article has multiple pages (that is, multiple sections) we have to break it down into separate XML files and send each of them through the style sheet.
We'll start with the easier of the two, a single page article.
'strArticleID is the article title minus punctuation and spaces
strFilePath = strArticleID & ".asp"
' Generate Pages for either Single Page or multiple pages
Set doc = xmlSource.documentElement
strTemp = doc.selectSinglenode("/article/meta/page_count").getAttribute("type")
Set xslStore = Server.CreateObject("MSXML2.DOMDocument.3.0")
xslStore.async = false
xslStore.load "article_style.xslt"
If CStr(strTemp) = "single" then
strArticle = xmlSource.transformNode(xslStore)
strArticle = Replace(strArticle, "html:", "")
If Not WriteToFile(strFilePath, strArticle, ForWriting, strError) then _
Exit Function
Something that we have to do here is take out all of the html namespace references for the browsers – remember, we allowed authors to use elements from the html namespace. The WriteToFile procedure uses a File System Object to write the ASP file to disk:
Function WriteToFile(strFile, strContents, strMethod, strError)
'Writes data to by overwriting or appending. If the file does
'not exist, it will try to be created.
'In Params:
' strFile - File to write data type
' strContents - data to write to the file
' strMethod - ForWriting or ForAppending
'Out Params:
' strError - error code
'Return Def:
' boolean: true if operation is a success
On Error Resume Next
WriteToFile = false
Dim objFSO, objTS
Set objFSO = Server.CreateObject("Scripting.FileSystemObject")
If objFSO.FileExists(strFile) Then
Set objTS = objFSO.OpenTextFile(strFile, strMethod)
objTS.WriteLine strContents
If Err.Number <> 0 Then
strError = Err.Description
Exit Function
End If
Else
Set objTS = objFSO.CreateTextFile(strFile)
If Err.Number <> 0 Then
strError = Err.Description
Exit Function
End If
objTS.WriteLine strContents
If Err.Number <> 0 Then
strError = Err.Description
Exit Function
End If
End If
WriteToFile = true
End Function
Dealing With Multi-page Articles
To understand how we generate multiple page articles, I think a chart would definitely be helpful.
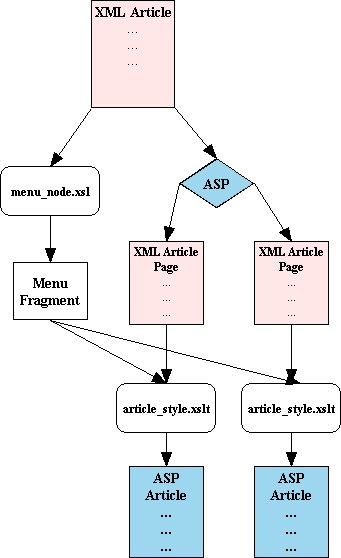
Each page will have a menu displaying all of the sections of the article. These will be based on the section's title attribute. This is what menu_node.xsl does: it goes through all of the sections and gets their title attribute. The names of the ASP article files will be:
etc.
Here's what menu_node.xsl looks like.
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"
xmlns:xp="http://www.w3.org/1999/XPath">
<xsl:template match="/">
<xsl:apply-templates />
</xsl:template>
<xsl:template match="/article">
<article_menu>
Then we generate a node for each category:
<xsl:for-each select="section">
<menu_item>
<link_title>
<xsl:value-of select="@title" />
</link_title>
And we generate an XML document that holds references to each page of the article:
<ref>
<xsl:eval>
TransformTitle(this.selectSingleNode("/article/meta/title").text)
</xsl:eval>
<xsl:eval>
if(ChildNumber(this) != 1)
ChildNumber(this)</xsl:eval>.asp
</ref>
</menu_item>
</xsl:for-each>
</article_menu>
</xsl:template>
The ref attribute holds the file names of each page of the article. It is based on the title of the article ( Article_title.asp , Article_title2.asp ). And as we don't want Article_title1.asp , we use the ChildNumber(this) conditional to determine whether to include a page number in the file name.
The TransformTitle function removes all spaces and non-alphanumeric characters with the help of some JScript regular expressions.
<!--Scripts-->
<xsl:script>
<![CDATA[
function TransformTitle(strVal) {
strVal = strVal.toLowerCase( );
strVal = strVal.replace(/\s/g, "_");
return strVal.replace(/([^a-z | _])/g, "");
}
]]>
</xsl:script>
</xsl:stylesheet>
The ASP Multi-page Logic
Now let's look at the ASP that uses this. The hardest thing to do is to coordinate the ASP and XSLT. In the XSLT, we refer to each section's filename. In the ASP, we actually create the files. We use the previous XSLT template to generate the menu fragment to put in each of our separate XML documents. We also need to append the meta element. So basically, our new XML documents will consist of three things:
The code in our GenerateArticle function looks like this:
Else
' Multiple Page Article
Dim strMenuProlog, xmlMenu, nodeMenu, xslMenu, xmlNew, strArticleProlog
Dim node2, nCounter, xmlMenu2, metaNode
strArticleProlog = "<?xml version=""1.0""?>" & "<article " & _
"xmlns=""x-schema:http://www.mydomain.com/Schemas/article.xsd"" " & _
"xmlns:html=""http://www.w3.org/1999/html"" />"
We set up our new XML document:
Set xmlNew = Server.CreateObject("MSXML2.DOMDocument.3.0")
xmlNew.load(strArticleProlog)
And the menu node:
Set xslMenu = Server.CreateObject("MSXML2.DOMDocument.3.0")
xslMenu.async =false
xslMenu.load "menu_node.xsl"
And build the article menu. We also need a clone to use for the other articles:
Set xmlMenu = Server.CreateObject("MSXML2.DOMDocument.3.0")
Set xmlMenu2 = Server.CreateObject("MSXML2.DOMDocument.3.0")
Remember, xmlSource is the beginning XML Article file:
Call xmlSource.transformNodetoObject(xslMenu, xmlMenu) Set xmlMenu2.documentElement = xmlMenu.documentElement.cloneNode(true)
Now we can build the first page. First, get the meta element:
Set node = doc.selectSinglenode("/article/meta")
Set metaNode = Server.CreateObject("MSXML2.DOMDocument.3.0")
Set metaNode.documentElement = node.cloneNode(true)
And now here are the three things that make the new document:
xmlNew.documentElement.appendChild(node)
Set node = doc.selectSinglenode("/article/section")
xmlNew.documentElement.appendChild(node)
xmlNew.documentElement.appendChild(xmlMenu.documentElement)
selectSinglenode("/article/section") gets the first section. We can then save the first page ( xslStore holds article_style.xslt – the style sheet used to transform XML documents into articles):
strTemp = xmlNew.transformNode(xslStore)
strTemp = Replace(strTemp, "html:", "")
Call WriteToFile(strFilePath, strTemp, ForWriting, strError)
set nodelist = doc.selectNodes("/article/section")
nCounter = 2
After we've generated the first page, we save it the same way we saved the first file. Now we loop through each section of the main article, creating the new XML document as we've done above, and save it. Following the filename convention we set up a little while ago, the article file names will be strArticleID & number & .asp :
For Each node In nodelist
Set xmlNew = Server.CreateObject("MSXML2.DOMDocument.3.0")
xmlNew.load(strArticleProlog)
' clone this node each time because we don't know how many
' times we'll need it
' node2 holds a copy of the meta element and
' node holds the section element
Set node2 = metaNode.documentElement.cloneNode(true)
xmlNew.documentElement.appendChild(node2)
xmlNew.documentElement.appendChild(node)
Set xmlMenu.documentElement = xmlMenu2.documentElement.cloneNode(true)
' append a copy of the menu node
xmlNew.documentElement.appendChild(xmlMenu.documentElement)
strFilePath = strArticleID & nCounter & ".asp"
strTemp = xmlNew.transformNode(xslStore)
strTemp = Replace(strTemp, "html:", "")
Call WriteToFile(strFilePath, strTemp, ForWriting, strError)
nCounter = nCounter + 1
Set xmlNew = Nothing
Next
This code is virtually the same as the code used to generate the first page of the article. The only difference is that node contains a different section element for each iteration. We also have to generate the new file name.
The same style sheet ( article_style.xslt ) is applied to multi-page articles and single page ones. Since each section will become it's own separate XML document, the only difference the XSLT style sheet will notice is the <page_count> attribute of the meta element, and the menu fragment that will include references to all of the other article sections.
article_style.xslt is too large to just dump into this article – you'll need to check out the code download if you want to see the whole file. However, we'll take a look at the linking structure here, which I think is the most interesting part.
At the bottom of each page, there are links to the previous article, if this isn't the first, and the next article, if this isn't the last. This is what the following fragment does:
<xsl:if test="/article/art:meta/art:page_count[@type = 'multiple']">
<xsl:for-each select="/article/article_menu/menu_item">
<xsl:if test="normalize-space(child::link_title) =
//art:section/@title">
<div align="right">
<xsl:if test="position() != 1">
<!--Previous Link-->
<a>
<xsl:attribute name="href">
<xsl:value-of select=
"normalize-space(preceding-sibling::*[position() = 1]/ref)" />
</xsl:attribute>
<
<xsl:value-of select=
"preceding-sibling::menu_item[position() = 1]/link_title" />
</a>|
</xsl:if>
<xsl:if test="position() != last()" >
<!--Next Link-->
<a>
<xsl:attribute name="href">
<xsl:value-of select=
"normalize-space(following-sibling::*[position() = 1]/ref)" />
</xsl:attribute>
<xsl:value-of select=
"following-sibling::menu_item[position() = 1]/link_title" />
>
</a>
</xsl:if>
</div>
</xsl:if>
</xsl:for-each>
Notice that we've had to include the namespaces in the text. This is because, unlike XSL, XSLT is namespace sensitive. Because we're using a schema definition, every article element is inside the schema namespace. In XSL, you don't have to do this.
To include the namespace, put a reference in the root element like:
xmlns:art="x-schema:http://www.mydomain.com/article.xsd"
The code above searches through all of the children of the article_menu element. When it finds one that matches itself (that is, it's found the link to itself in the menu), it displays links using preceding-sibling and following-sibling . This is new to XSLT. In XSL, it would be a lot more complicated.
Also, notice the use of normalize-space . When checking equality for node values, white space is taken into account. Normalize-space removes contiguous white space.
Everything that needs to be done for multi-page articles and not for single page articles can be done in a test to the page_count element. This is also one of the reasons for including the meta element inside each section XML document.
While developing this system, I wanted authors to be able to execute code samples that they put inside their articles. I also wanted to use SSI the way I had been doing since I got involved with ASP. These two things are the reason I said ASP article, and not just plain HTML. The XSLT template that matches the code elements is below. It allows authors to have their code executed via an execute attribute:
<xsl:template match="art:code">
<pre>
<code>
<xsl:value-of select="." />
</code>
</pre>
<xsl:if test="@execute = 'yes'">
<div>
<xsl:value-of disable-output-escaping="yes" select="." />
</div>
</xsl:if>
</xsl:template>
The trick is the disable-output-escaping attribute of the xsl:value-of element. When this is set to yes , all of the text is not escaped for the browser. For example <% does not become <% .
Using SSI in XSLT is very simple. Just use the xsl:comment element like so:
<xsl:comment>#include file="filename.asp"</xsl:comment>
Since authors are able to use any HTML element, we use a recursive template to copy all of the html elements from the XML source to the output. Here is how we do that:
<xsl:template match="html:* | @*">
<xsl:copy>
<xsl:apply-templates select="@* | *" />
<xsl:value-of select="." />
</xsl:copy>
</xsl:template>
This template matches any element in the html namespace and the attributes of those elements. Then all child elements get the same template applied to them for embedded HTML tags.
In actual production code, you should have some kind of mechanism that doesn't allow all HTML elements. Authors could really mess up the way the page is supposed to look. You could write templates for all of the elements you wanted, therefore ignoring all other elements, or program the checking into ASP before the article makes it to the style sheet.
Now that there is a mechanism to generate articles, the only thing left to do is build a web site around them. Given the structure of the data, this would not be very difficult to implement at all. There could be ASP pages set up for each category. These pages will apply a style sheet to their corresponding category store file, and the ways you can display the data are endless.
With the code download for this article, I have supplied a sample XSLT that transforms the article list into a select box that is used to view the articles. This is implemented in articleloader.asp and article_selectlist.xsl . Because of the rigid format of the category stores, you could even dynamically generate these ASP pages that displayed articles in each category. The only thing that would be different is the category file name. When I was working on this system, I wanted to create a web site that practically ran itself. If I wanted a new category, I could do it via an HTML form. If I wanted to post a new article, I could just upload an XML file. Here are some other ideas that such a system could dynamically implement:
Well, that's all there is to building our flexible content management application using XML and its related technologies. I hope that I've shown some practical implementation for those of us in the real world, as well as giving you some ideas of how you could adapt this solution for your own ends.
Of course, it's important to remember that XML is still a rapidly evolving technology. Be sure to check up on the W3C website to keep that edge.
|
| |||||||
|
|||||||||||||||||||||||||||
| |||||||||||||||
|
| ASPToday is brought to you by
Wrox Press (http://www.wrox.com/). Please see our terms
and conditions and privacy
policy. ASPToday is optimised for Microsoft Internet Explorer 5 browsers. Please report any website problems to webmaster@asptoday.com. Copyright © 2001 Wrox Press. All Rights Reserved. |
